Partie 15 : Monitoring — Prometheus, Grafana et AlertManager sur K3s
Février 2026
Le constat : un cluster aveugle
Depuis le début de ce projet, le cluster K3s tourne en production avec Home Assistant, Passbolt, le blog Ghost, le arr-stack... mais sans aucune visibilité sur la santé des pods et des nœuds.
Le problème est devenu flagrant lors de la bascule de Passbolt en production : MySQL avait accumulé 171 échecs de readiness probe et 5 redémarrages sur 19 jours. Kubernetes avait corrigé silencieusement grâce à l'auto-healing, mais sans monitoring, impossible de savoir que quelque chose clochait.
Il est temps d'y remédier.
L'objectif
Déployer une stack de monitoring complète pour :
- Collecter les métriques du cluster (CPU, RAM, disque, état des pods)
- Visualiser tout ça dans des dashboards
- Alerter quand quelque chose ne va pas (avant que ça ne casse)
Le choix technique : kube-prometheus-stack
Après avoir évalué plusieurs options (installation séparée, Victoria Metrics), le choix se porte sur kube-prometheus-stack, le chart Helm tout-en-un de la communauté Prometheus :
| Composant | Rôle |
|---|---|
| Prometheus | Collecte et stockage des métriques |
| Grafana | Dashboards et visualisation |
| AlertManager | Gestion et routage des alertes |
| Node Exporter | Métriques système de chaque nœud (CPU, RAM, disque) |
| Kube State Metrics | Métriques Kubernetes (pods, deployments, etc.) |
| Prometheus Operator | Gère la configuration de Prometheus via des CRDs |
C'est le standard de facto pour le monitoring Kubernetes, avec des dashboards préconfigurés et des alertes par défaut.
La contrainte : Raspberry Pi
Le cluster tourne sur des Raspberry Pi avec des ressources limitées :
| Node | RAM | Rôle |
|---|---|---|
| rpi4-master | 8 GB | Control plane + services critiques |
| rpi4-worker | 2 GB | Home Assistant, Passbolt |
| rpi4-worker2 | 4 GB | arr-stack (VPN pod) |
| rpi3-worker1 | 1 GB | Workloads légers |
| rpi3-worker2 | 1 GB | Workloads légers |
La stack monitoring sera donc optimisée en ressources et déployée principalement sur rpi4-master (le nœud avec le plus de RAM disponible).
Structure des fichiers
helm-charts/monitoring/
├── Chart.yaml # Chart wrapper
├── values.yaml # Configuration optimisée RPi
└── templates/
├── alerts.yaml # Alertes personnalisées
└── sealed-secret-grafana.yaml # Credentials Grafana (chiffré)
argocd-apps/applications/
└── monitoring.yaml # Application ArgoCD
Étape 1 : Le Chart Helm
Le monitoring est packagé comme un chart Helm "umbrella" qui wrape kube-prometheus-stack en tant que dépendance :
Fichier : helm-charts/monitoring/Chart.yaml
apiVersion: v2
name: monitoring
description: Stack de monitoring pour cluster K3s RPi (Prometheus, Grafana, AlertManager)
type: application
version: 1.0.0
appVersion: "1.0.0"
dependencies:
- name: kube-prometheus-stack
version: "68.4.5"
repository: https://prometheus-community.github.io/helm-charts
Le chart upstream est en version 68.4.5. ArgoCD se chargera automatiquement du helm dependency build.
Étape 2 : La configuration (values.yaml)
C'est le fichier le plus important. Chaque section est pensée pour les contraintes RPi.
Composants K3s désactivés
K3s intègre certains composants différemment de Kubernetes vanilla. Ces exporters ne trouveraient pas leurs cibles :
kube-prometheus-stack:
kubeEtcd:
enabled: false # K3s utilise SQLite, pas etcd
kubeControllerManager:
enabled: false # Pas accessible sur K3s
kubeScheduler:
enabled: false # Pas accessible sur K3s
kubeProxy:
enabled: false # K3s gère kube-proxy différemment
Prometheus
prometheus:
prometheusSpec:
resources:
requests:
memory: 256Mi
cpu: 100m
limits:
memory: 512Mi
cpu: 500m
retention: 7d # 7 jours de rétention
retentionSize: "5GB" # Maximum 5 GB sur disque
scrapeInterval: 30s # Bon compromis perf/précision sur RPi
evaluationInterval: 30s
# Stockage persistant (survit aux redémarrages)
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
# Déployer sur le master (le plus de RAM)
nodeSelector:
kubernetes.io/hostname: rpi4-master
# Scraper TOUS les namespaces, pas seulement celui du release
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
probeSelectorNilUsesHelmValues: false
Les 4 lignes *NilUsesHelmValues: false sont essentielles : sans elles, Prometheus ne scraperait que les ServiceMonitors et PrometheusRules du namespace monitoring. On veut qu'il scrape tout le cluster.
Grafana
grafana:
enabled: true
resources:
requests:
memory: 128Mi
cpu: 50m
limits:
memory: 256Mi
cpu: 200m
# Mot de passe admin via SealedSecret (pas en clair dans Git !)
admin:
existingSecret: grafana-admin-credentials
userKey: admin-user
passwordKey: admin-password
# Déployer sur le master
nodeSelector:
kubernetes.io/hostname: rpi4-master
# Ingress avec TLS
ingress:
enabled: true
ingressClassName: nginx
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod-dns
nginx.ingress.kubernetes.io/ssl-redirect: "true"
hosts:
- grafana.home-fonta.fr
tls:
- secretName: grafana-home-fonta-tls
hosts:
- grafana.home-fonta.fr
# Persistance pour les dashboards et la config
persistence:
enabled: true
storageClassName: local-path
size: 1Gi
defaultDashboardsTimezone: Europe/Paris
plugins:
- grafana-piechart-panel
Le mot de passe admin est stocké dans un SealedSecret. Cert-manager génère automatiquement le certificat TLS pour grafana.home-fonta.fr.
AlertManager
alertmanager:
alertmanagerSpec:
resources:
requests:
memory: 64Mi
cpu: 25m
limits:
memory: 128Mi
cpu: 100m
nodeSelector:
kubernetes.io/hostname: rpi4-master
storage:
volumeClaimTemplate:
spec:
storageClassName: local-path
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
# Routage des alertes (placeholder, Discord sera configuré plus tard)
config:
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'null'
receivers:
- name: 'null'
Pour l'instant, les alertes sont routées vers un receiver null (elles sont enregistrées mais pas envoyées). La configuration Discord viendra dans une prochaine phase.
Node Exporter et Kube State Metrics
# Node Exporter : DaemonSet sur TOUS les nœuds
nodeExporter:
enabled: true
prometheus-node-exporter:
resources:
requests:
memory: 32Mi
cpu: 10m
limits:
memory: 64Mi
cpu: 50m
# Kube State Metrics : sur le master uniquement
kube-state-metrics:
resources:
requests:
memory: 64Mi
cpu: 10m
limits:
memory: 128Mi
cpu: 100m
nodeSelector:
kubernetes.io/hostname: rpi4-master
Le Node Exporter tourne en DaemonSet (un pod par nœud) pour collecter les métriques système de chaque Raspberry Pi. Les ressources sont volontairement basses (32-64 Mi) pour ne pas impacter les RPi3 qui n'ont que 1 GB de RAM.
Bilan des ressources
| Composant | Requests | Limits | Nœud |
|---|---|---|---|
| Prometheus | 256Mi / 100m | 512Mi / 500m | master |
| Grafana | 128Mi / 50m | 256Mi / 200m | master |
| AlertManager | 64Mi / 25m | 128Mi / 100m | master |
| Prometheus Operator | 128Mi / 50m | 256Mi / 200m | master |
| Kube State Metrics | 64Mi / 10m | 128Mi / 100m | master |
| Node Exporter (x5) | 32Mi / 10m | 64Mi / 50m | tous |
Total sur rpi4-master : ~640Mi requests, ~1280Mi limits
Total par worker (node-exporter) : ~32Mi requests, ~64Mi limits
Étape 3 : Les alertes personnalisées
En plus des alertes par défaut du kube-prometheus-stack, on ajoute des règles spécifiques à notre cluster.
Fichier : helm-charts/monitoring/templates/alerts.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: custom-alerts
labels:
app: kube-prometheus-stack
release: {{ .Release.Name }}
spec:
groups:
# Santé des pods
- name: pod-health
rules:
- alert: PodRestartingTooOften
expr: increase(kube_pod_container_status_restarts_total[24h]) > 1
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.pod }} redémarre trop souvent"
description: "Le pod {{ $labels.pod }} dans {{ $labels.namespace }} a redémarré {{ $value }} fois en 24h"
- alert: PodCrashLoopBackOff
expr: kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} > 0
for: 5m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.pod }} en CrashLoopBackOff"
- alert: PodNotReady
expr: kube_pod_status_ready{condition="true"} == 0
for: 10m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.pod }} non prêt depuis 10 minutes"
# Santé des nœuds
- name: node-health
rules:
- alert: NodeMemoryHigh
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "Mémoire haute sur {{ $labels.instance }}"
- alert: NodeDiskSpaceLow
expr: (1 - (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes)) > 0.80
for: 5m
labels:
severity: warning
annotations:
summary: "Espace disque faible sur {{ $labels.instance }}"
- alert: NodeCPUHigh
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: warning
annotations:
summary: "CPU élevé sur {{ $labels.instance }}"
# Certificats SSL
- name: certificates
rules:
- alert: CertificateExpiringSoon
expr: certmanager_certificate_expiration_timestamp_seconds - time() < 1209600
for: 1h
labels:
severity: warning
annotations:
summary: "Certificat {{ $labels.name }} expire dans moins de 14 jours"
Ces alertes couvrent les scénarios les plus critiques :
- PodRestartingTooOften : Exactement ce qu'on aurait voulu avoir pour MySQL/Passbolt
- PodCrashLoopBackOff : Alerte critique, l'application est cassée
- NodeMemoryHigh/DiskSpaceLow/CPUHigh : Anticiper les problèmes de ressources sur les RPi
- CertificateExpiringSoon : Éviter les erreurs HTTPS par oubli de renouvellement
Étape 4 : Le SealedSecret pour Grafana
Le mot de passe admin de Grafana ne doit pas être en clair dans Git. On utilise SealedSecrets :
# 1. Créer le secret en dry-run
kubectl create secret generic grafana-admin-credentials \
--namespace=monitoring \
--from-literal=admin-user=admin \
--from-literal=admin-password=MON_MOT_DE_PASSE \
--dry-run=client -o yaml | \
kubeseal --controller-name=sealed-secrets-controller \
--controller-namespace=kube-system --format yaml \
> helm-charts/monitoring/templates/sealed-secret-grafana.yaml
Le fichier généré contient les données chiffrées. Seul le contrôleur SealedSecrets dans le cluster peut les déchiffrer.
Étape 5 : L'application ArgoCD
Comme toutes les applications du cluster, le monitoring est déployé via ArgoCD avec le pattern App of Apps.
Fichier : argocd-apps/applications/monitoring.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: monitoring
namespace: argocd
spec:
project: default
source:
repoURL: git@github.com:Nikob2o/ansible-k3s.git
targetRevision: HEAD
path: helm-charts/monitoring
helm:
valueFiles:
- values.yaml
destination:
server: https://kubernetes.default.svc
namespace: monitoring
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
- ServerSideApply=true
ServerSideApply=true est important ici : le kube-prometheus-stack installe des CRDs volumineuses, et sans Server-Side Apply, on risque des erreurs de taille d'annotation.
Déploiement
Un simple commit et push suffit. ArgoCD détecte automatiquement les nouveaux fichiers et lance le déploiement :
git add helm-charts/monitoring/ argocd-apps/applications/monitoring.yaml
git commit -m "Ajout du monitoring"
git push
ArgoCD fait le reste : il télécharge la dépendance kube-prometheus-stack, génère les manifests et les applique dans le namespace monitoring.
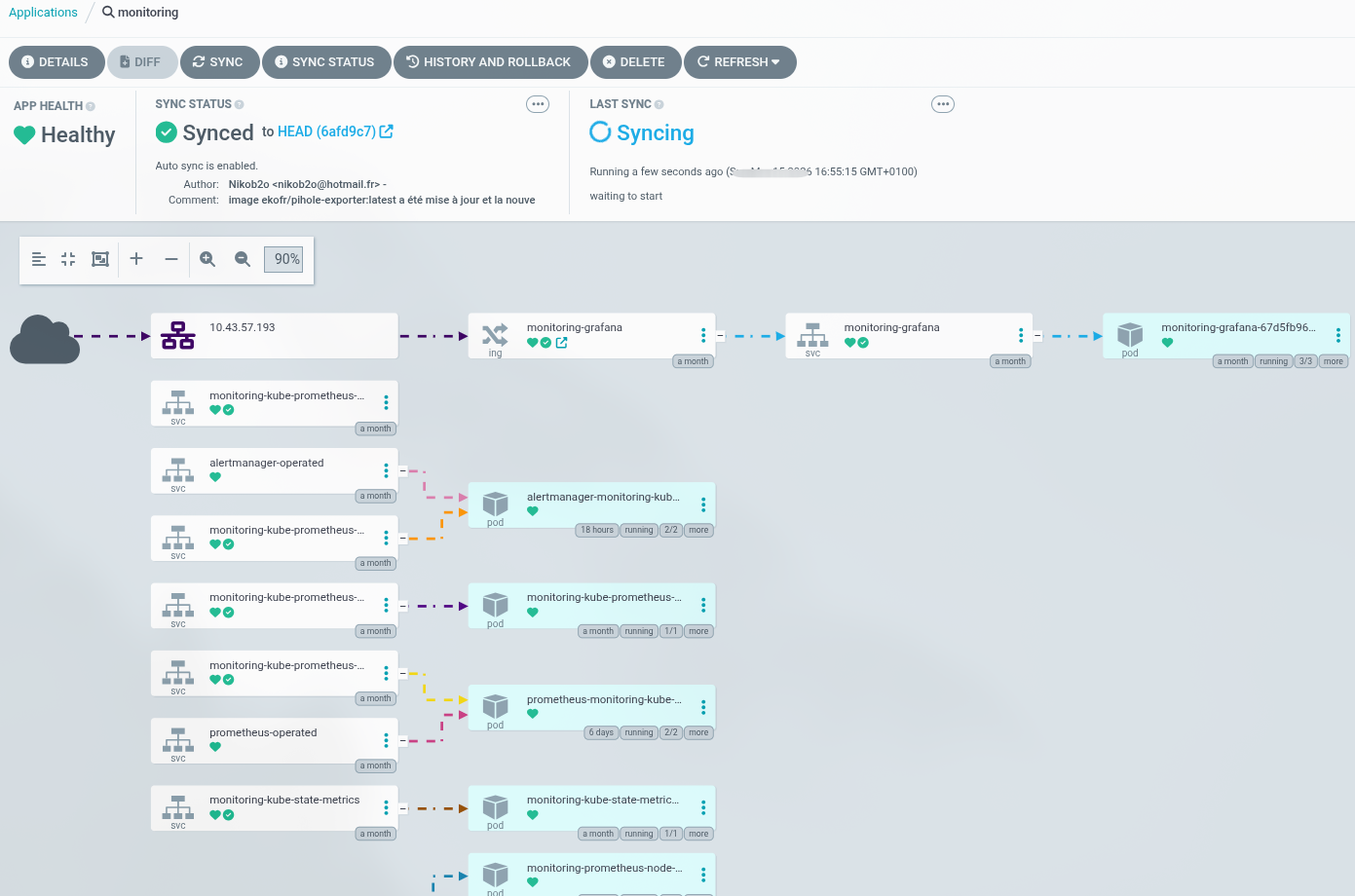
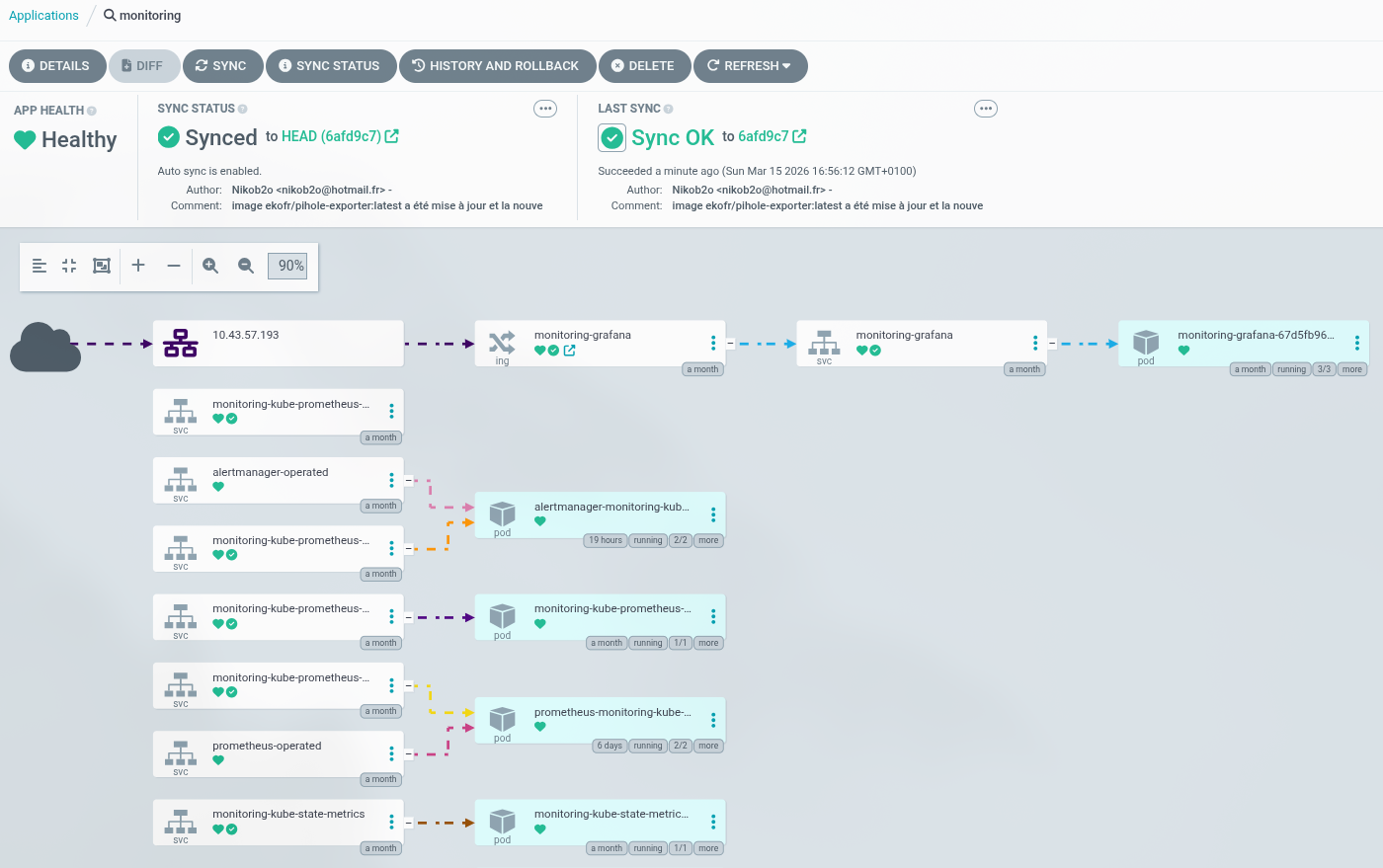
Vérification
Pods
kubectl get pods -n monitoring
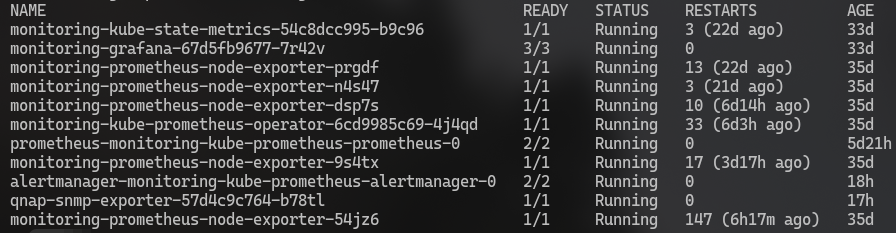
Tous les pods doivent être en Running :
monitoring-prometheus-0— Prometheusmonitoring-grafana-xxx— Grafanamonitoring-alertmanager-0— AlertManagermonitoring-prometheus-node-exporter-xxx(x5) — Un par nœudmonitoring-kube-state-metrics-xxx— Kube State Metricsmonitoring-kube-prometheus-operator-xxx— L'opérateur
Stockage
kubectl get pvc -n monitoring

Ingress
kubectl get ingress -n monitoring

Accès à Grafana
Ouvrir https://grafana.home-fonta.fr dans le navigateur et se connecter avec les credentials définis dans le SealedSecret.
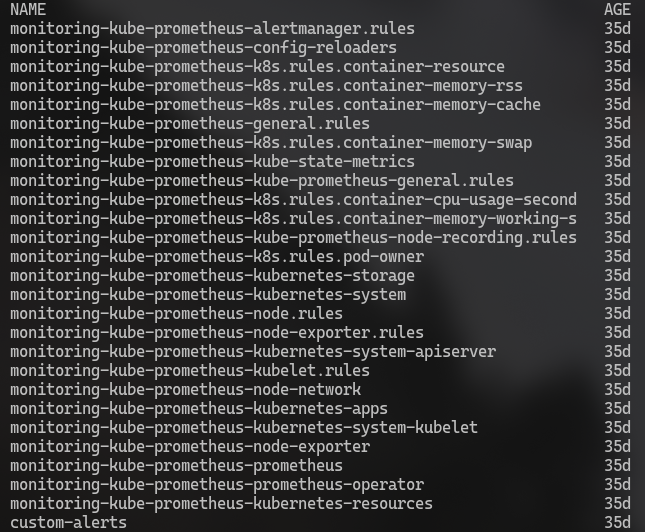
Alertes personnalisées
kubectl get prometheusrules -n monitoring
Prometheus UI (optionnel, via port-forward)
kubectl port-forward -n monitoring svc/monitoring-kube-prometheus-prometheus 9090:9090
Puis ouvrir http://localhost:9090 pour vérifier que Prometheus scrape bien toutes les cibles.
Architecture déployée
┌─────────────────────────────────────────────────────────────────────────┐
│ Cluster K3s │
│ │
│ rpi4-master (8GB) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Prometheus │ │ Grafana │ │ AlertManager │ │
│ │ 512Mi max │ │ 256Mi max │ │ 128Mi max │ │
│ │ 10Gi disque │ │ 1Gi disque │ │ 1Gi disque │ │
│ └──────┬───────┘ └──────────────┘ └──────────────┘ │
│ │ │
│ │ scrape toutes les 30s │
│ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Métriques collectées │ │
│ │ - kube-state-metrics (pods, deployments...) │ │
│ │ - node-exporter x5 (CPU, RAM, disque) │ │
│ │ - kubelet metrics │ │
│ │ - cert-manager metrics │ │
│ └──────────────────────────────────────────────────┘ │
│ │
│ Tous les nœuds : node-exporter (32-64Mi) │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ master │ │worker1 │ │worker2 │ │ rpi3-1 │ │ rpi3-2 │ │
│ └────────┘ └────────┘ └────────┘ └────────┘ └────────┘ │
└─────────────────────────────────────────────────────────────────────────┘
Ce qui reste à faire
La stack de base est en place, mais il reste encore du travail :
| Phase | Description | Statut |
|---|---|---|
| 6.1 | Installation Prometheus + Grafana + AlertManager | Terminé |
| 6.2 | Dashboards Grafana personnalisés | A faire |
| 6.3 | Alertes Discord | A faire |
Prochain article : Partie 16 — Dashboards Grafana personnalisés