Partie 18 : Alertes Discord — AlertManager notifie en temps réel
Mars 2026
Le besoin
Les dashboards Grafana c'est bien, mais il faut penser à les regarder. Quand un pod crashloop à 3h du matin, quand un disque du NAS commence à lâcher, ou quand un nœud atteint 95% de disque — on veut être prévenu immédiatement, sans devoir ouvrir Grafana.
AlertManager est déjà déployé dans le cluster depuis la Partie 15 (il fait partie de kube-prometheus-stack), mais il envoyait toutes les alertes vers null — autrement dit, il les avalait en silence. L'idée : brancher Discord comme canal de notification, avec un routing intelligent pour envoyer les alertes au bon endroit.
Architecture
La chaîne d'alerte
Prometheus AlertManager Discord
┌───────────────┐ ┌──────────────┐ ┌─────────────┐
│ PrometheusRule │──firing──▶│ Routing │──webhook──▶│ #alertes │
│ (alertes) │ │ │ │ (cluster) │
│ │ │ category: │ ├─────────────┤
│ qnap_* rules │──firing──▶│ nas → fonas │──webhook──▶│ #fonas │
│ │ │ │ │ (NAS) │
└───────────────┘ │ Watchdog │ └─────────────┘
│ → null │
└──────────────┘
Quatre receivers :
discord: salon principal, reçoit les alertes cluster (pods, nœuds, certificats)discord-fonas: salon #fonas, reçoit les alertes NAS (SNMP/QNAP)plex: Plexnull: poubelle pour les alertes internes (Watchdog)
Le problème des secrets dans un repo GitOps
Les URLs de webhook Discord contiennent des tokens d'authentification. On ne peut pas les mettre en clair dans values.yaml — le repo est sur GitHub.
La solution classique serait de mettre l'URL dans un Secret Kubernetes et de la référencer dans la config AlertManager. Mais l'operator Prometheus fait les choses différemment : il valide et reconstruit la config AlertManager lui-même. Si on utilise webhook_url_file (référence à un fichier monté), l'operator refuse avec no discord webhook URL provided.
La solution : utiliser alertmanagerSpec.configSecret. Au lieu de laisser Helm générer la config AlertManager, on fournit un Secret Kubernetes complet contenant tout le fichier alertmanager.yaml — y compris les URLs webhook. Ce Secret est créé via un SealedSecret (chiffré dans git, déchiffré uniquement par le cluster).
# values.yaml — on pointe vers un Secret externe
alertmanager:
alertmanagerSpec:
configSecret: alertmanager-config
# Création du SealedSecret
kubectl create secret generic alertmanager-config \
--from-file=alertmanager.yaml=/tmp/alertmanager.yaml \
--namespace=monitoring \
--dry-run=client -o yaml | kubeseal --format yaml \
> templates/sealed-secret-alertmanager-config.yaml
Le fichier alertmanager.yaml contient la config complète (routing + receivers + URLs webhook), mais une fois scellé, seul le cluster peut le déchiffrer.
Les alertes définies
Alertes cluster
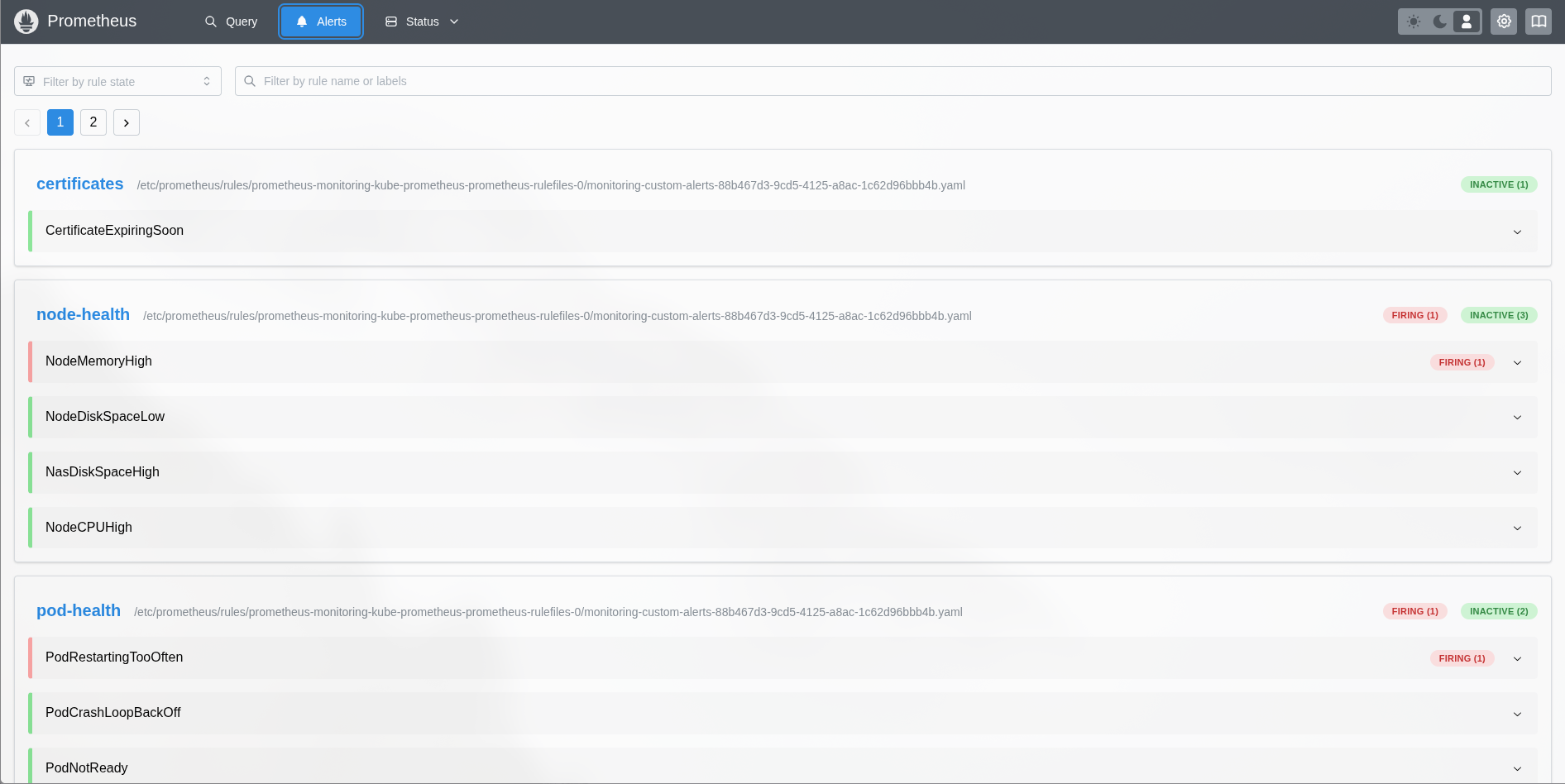
Définies dans templates/alerts.yaml sous forme de PrometheusRule :
| Alerte | Condition | Sévérité | Délai |
|---|---|---|---|
| PodCrashLoopBackOff | Pod en CrashLoopBackOff | critical | 5 min |
| PodRestartingTooOften | > 3 restarts en 24h | warning | 5 min |
| PodNotReady | Pod non prêt | warning | 10 min |
| NodeMemoryHigh | RAM > 85% | warning | 5 min |
| NodeDiskSpaceLow | Disque local > 85% | warning | 5 min |
| NodeCPUHigh | CPU > 90% | warning | 5 min |
| CertificateExpiringSoon | Certificat expire dans < 14 jours | warning | 1 h |
Toutes les annotations sont en français :
- alert: PodCrashLoopBackOff
expr: kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} > 0
for: 5m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.pod }} en CrashLoopBackOff"
description: "Le pod {{ $labels.pod }} dans {{ $labels.namespace }}
est en CrashLoopBackOff depuis 5 minutes"
Alertes NAS (QNAP)
Routées vers le salon #fonas grâce au label category: nas :
| Alerte | Condition | Sévérité | Délai |
|---|---|---|---|
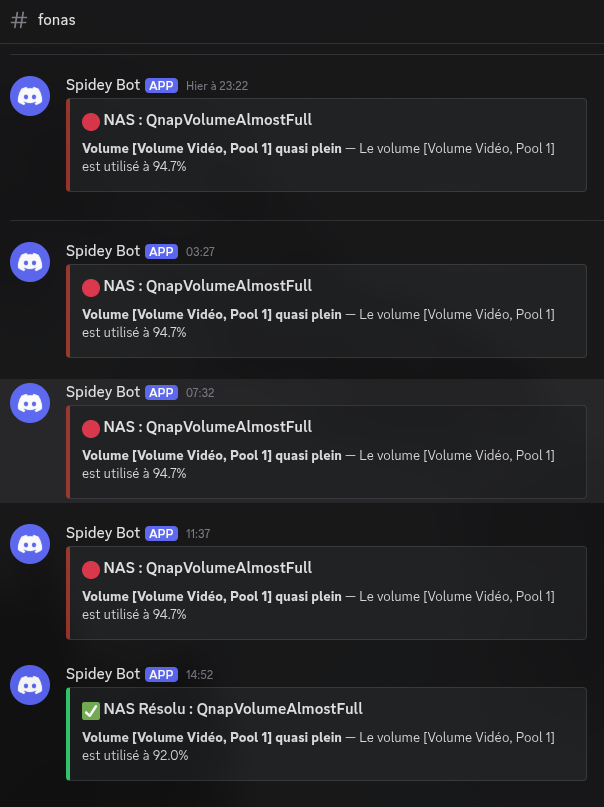
| QnapVolumeAlmostFull | Volume > 90% utilisé | warning | 10 min |
| QnapDiskUnhealthy | SMART ≠ GOOD | critical | 5 min |
| QnapDiskTemperatureHigh | Disque > 50°C | warning | 5 min |
| QnapFanStopped | Ventilateur à 0 RPM | critical | 5 min |
| QnapUnreachable | NAS ne répond plus au SNMP | critical | 5 min |
Les métriques QNAP viennent du snmp-exporter. Exemple d'alerte :
- alert: QnapDiskTemperatureHigh
expr: qnap_disk_temperature_celsius{instance="192.168.1.18"} > 50
for: 5m
labels:
severity: warning
category: nas
annotations:
summary: "Disque {{ $labels.disk_name }} en surchauffe"
description: "Le disque {{ $labels.disk_name }} est à {{ $value }}°C
(seuil : 50°C)"
Alertes désactivées
L'alerte built-in CPUThrottlingHigh de kube-prometheus-stack a été désactivée. Sur des Raspberry Pi, le CPU throttling est constant pour les petits sidecars (node-exporter, exportarr) dont les limits sont volontairement basses. Ces alertes sont bruyantes et non actionnables.
defaultRules:
disabled:
CPUThrottlingHigh: true
Alerte NAS vs alerte NFS
L'alerte NodeDiskSpaceLow excluait initialement le montage NFS du NAS (qui remontait comme un disque local à 95%). Je l'ai séparée en deux alertes distinctes :
NodeDiskSpaceLow: disques locaux des RPi uniquement (fstype!~"nfs.*", seuil 85%)NasDiskSpaceHigh: montage NFS uniquement (fstype=~"nfs.*", seuil 95%)
Ça évite les faux positifs tout en gardant la visibilité sur le stockage NAS.
Configuration AlertManager
Routing
route:
group_by: ['alertname', 'namespace']
group_wait: 30s # Attendre 30s pour grouper les alertes similaires
group_interval: 5m # Minimum 5 min entre deux notifications du même groupe
repeat_interval: 4h # Re-notifier toutes les 4h si non résolu
receiver: 'discord' # Receiver par défaut
routes:
- match:
alertname: Watchdog
receiver: 'null' # Heartbeat interne → silence
- match:
category: nas
receiver: 'discord-fonas' # Alertes NAS → salon dédié
Pourquoi ces valeurs ?
group_wait: 30s: si 5 pods crashent en même temps, on reçoit une seule notification groupée au lieu de 5repeat_interval: 4h: assez long pour ne pas spammer, assez court pour ne pas oublier un problème- Le routing par label
category: naspermet d'ajouter facilement d'autres catégories plus tard (ex:category: media→ salon dédié)
Receivers Discord
receivers:
- name: 'discord'
discord_configs:
- webhook_url: '<URL scellée dans le SealedSecret>'
title: >-
{{ if eq .Status "firing" }}🔴 Alerte : {{ .CommonLabels.alertname }}
{{ else }}✅ Résolu : {{ .CommonLabels.alertname }}{{ end }}
message: >-
{{ range .Alerts }}**{{ .Annotations.summary }}** —
{{ .Annotations.description }}{{ end }}
send_resolved: true
- name: 'discord-fonas'
discord_configs:
- webhook_url: '<URL scellée dans le SealedSecret>'
title: >-
{{ if eq .Status "firing" }}🔴 NAS : {{ .CommonLabels.alertname }}
{{ else }}✅ NAS Résolu : {{ .CommonLabels.alertname }}{{ end }}
message: >-
{{ range .Alerts }}**{{ .Annotations.summary }}** —
{{ .Annotations.description }}{{ end }}
send_resolved: true
Le titre des notification n'est pas trop intuitif et un peu long, a terme je chercherai une meilleur façon pour me notifier des alertes avec un titre propre.
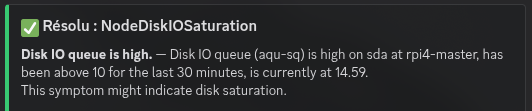
Le champ send_resolved: true est important : quand un problème est corrigé, Discord reçoit un message ✅ Résolu — on sait que c'est réglé sans devoir vérifier manuellement.

Le salon #fonas
Les alertes NAS ont leur propre salon Discord. C'est un choix de confort : les alertes cluster (pods, nœuds) et les alertes infrastructure (NAS, disques) ne concernent pas forcément les mêmes personnes ou les mêmes actions. Séparer les canaux permet de filtrer le bruit et de retrouver l'historique plus facilement.
Fichiers créés / modifiés
| Fichier | Modification |
|---|---|
templates/alerts.yaml |
+5 alertes QNAP, séparation disque local/NFS, annotations françaises |
templates/sealed-secret-alertmanager-config.yaml |
Config AlertManager complète avec 2 webhooks Discord |
values.yaml |
configSecret: alertmanager-config, désactivation CPUThrottlingHigh |
Récap
| Élément | Détail |
|---|---|
| Canal cluster | Discord — salon principal |
| Canal NAS | Discord — salon #fonas |
| Alertes cluster | 7 règles (pods, nœuds, certificats) |
| Alertes NAS | 5 règles (volumes, disques, température, ventilateur, joignabilité) |
| Routing | Par label category — extensible |
| Secrets | SealedSecret contenant toute la config AlertManager |
| Grouping | Par alertname + namespace, wait 30s, repeat 4h |
| Résolution | send_resolved: true — notification quand le problème est corrigé |
Techniques clés
- AlertManager
configSecretpour contourner la validation de l'operator - Routing par labels pour dispatcher vers différents salons Discord
send_resolved: truepour les notifications de résolution- Désactivation sélective des alertes built-in bruyantes (
CPUThrottlingHigh) - Séparation des alertes disque local / NFS pour éviter les faux positifs